Writing on software, systems, and hard-won lessons.
Writing on developer experience, systems thinking, and the mistakes behind both - covering AI workflows, continuous improvement, and the mental models that drive better decisions.

Writing on software, systems, and hard-won lessons.
Writing on developer experience, systems thinking, and the mistakes behind both - covering AI workflows, continuous improvement, and the mental models that drive better decisions.
At work someone asked how to rank higher. I said wrong question, first check if you're sabotaging yourself. The most common problem is people make it harder for Google to find and/or understand what their site is about.
I tried some SEO score sites, but they gave too much information. I just wanted to see the factors that were hurting the most. That's when I thought this might be a fun project to work on. I didn't have 5 weeks to build this by hand, I had 5 hours at best.
This project only succeeded because most of the work was planning, not coding. The second most important factor was knowing when to bring in multiple AI models to argue and critique each other.
https://self-sabotage.seoservices.nz
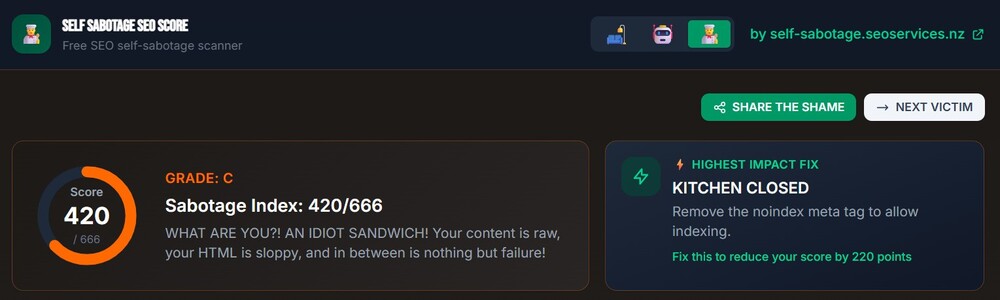
The goal is for you to enter your website URL, and the tool will scan for common SEO self-sabotage issues. There's already lots of SEO audit tools, but I wanted to build something that was quick, fun, and gave actionable advice.
After the initial plan, I thought it seemed too boring and wanted to add some personality. That's when I came up with the idea of roasting the user in different voices based on their self-sabotage score.
I was eating a bao, reading about event-driven orchestration, and thinking about a good name for when to bring in multiple AI models to collaborate. That's when I came up with the name Signal-Based Adaptive Orchestration (SBAO), which is basically: something feels off, so bring in more AIs to help.
If you want to read more about this, I wrote an article here: Signal-Based Adaptive Orchestration: When to Ask a Second AI
Architecture Pivot:
This project started with an initial plan using AWS S3 + CloudFront, based on a site I'd built a few years ago for a friend.
I first gave the plan to Claude to review and map out the tasks in more detail. Claude warned about CORS/SSRF issues. Suggested Cloudflare instead.
Pivoting from the familiar AWS stack to Cloudflare felt annoying and didn't want the extra effort, so I brought in Codex, Gemini, and Grok to review the plan. Grok roasted me: "S3 + CloudFront? That was cool in 2019." The others agreed, less colourfully.
Theme Tournament:
While reviewing the plans, the Sniff Test kicked in. The project was just too boring, so I decided to add some personalities.
I had a couple of ideas and then asked them to brainstorm personalities independently, then rank them. Detective was my initial idea, but after the brainstorming sessions I agreed there were better options. Disappointed Therapist ranked 1st across models and HAL 9000 style Sentient Algorithm 2nd. Then I really liked their idea of an Angry Chef, so picked that even though it ranked 5th.
I just couldn't resist that "Idiot Sandwich" energy!
Detector Scoring:
While testing I spotted a problem where the numbers seem a bit too low for bad sites and a bit high for good sites. I questioned if the scores are calibrated for best practice or calibrated for self-sabotaging discovery?
The Loophole: Even "the world's worst website" only hit 485/666, meaning no one would ever hit 666 (the viral certificate hook). Meanwhile, Harvard was scoring 140 (too high for a reputable site).
I asked Codex, Grok, and Gemini for calibration ideas, then cherry-picked:
Good sites dropped, bad sites stayed high or increased. The loophole was closed.
AI coding agents are fast, but they don't know what you know. Without upfront planning, an agent will confidently scaffold an entire architecture around the wrong assumptions. And you won't notice unt...
What is claude insights: The /insights command in Claude Code generates an HTML report analysing your usage patterns across all your Claude Code sessions. It's designed to help us understand how we in...
A friend of mine recently attended an open forum panel about how engineering orgs can better support their engineers. The themes that came up were not surprising: